
Pilot Purgatory: Why AI Demos Fail to Scale
Demos show capability; production requires reliability. Most companies optimise for the former and die in the latter.
The reason most project demos fail to scale is a structural disconnect. A demo is merely a proof of possibility, whereas production is a proof of utility. A model can easily perform a task in a controlled vacuum, but scaling that task requires it to survive the messy real-world reality of specific security, cost, and legal frameworks. When you build around the impression of impressive results and technical novelty rather than structural constraints, you aren’t building a scalable system; you are building a weak wrapper that shatters the moment it hits the friction of a real-world workflow.
Dear Pilot, Meet Purgatory
Despite the initial hype, research from MIT indicates that only 10% of organisations achieve significant financial benefits from their AI investments. This sobering reality stems from the fact that most enterprise GenAI initiatives do not fail loudly; they simply stall. After an initial burst of excitement, these projects linger in a half-deployed state, performing well enough to demonstrate potential in a sandbox, but failing to survive the scrutiny of a production-ready environment.
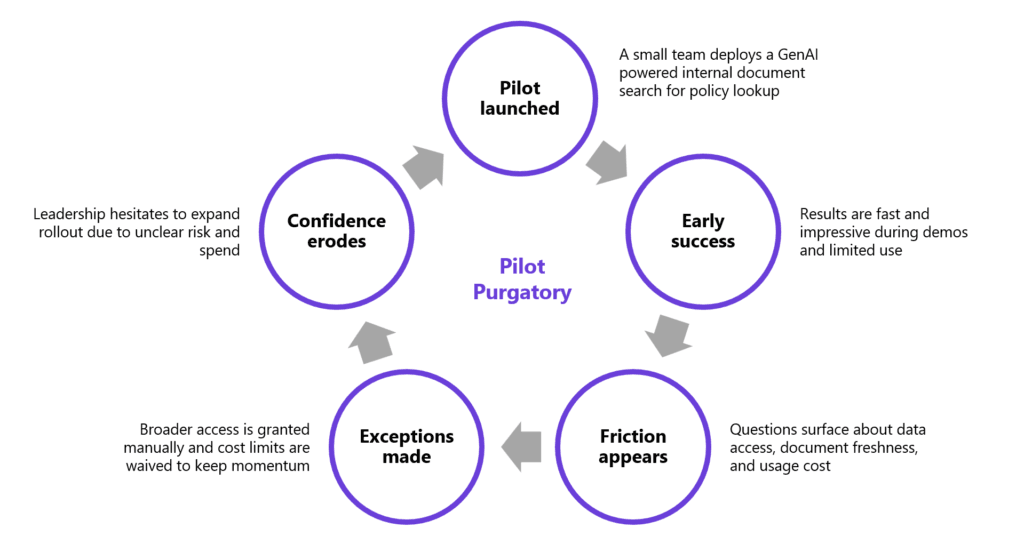
This stagnation is fundamentally an incentive problem. In many organisations, internal projects are fueled by a desire for immediate visibility and “innovation theatre” rather than durable stewardship. Instead of focusing on “shiny“ deliverables and chasing the most “capable models,“ project managers should prioritise:
- Operational Integrity: Ensuring the system remains reliable under the stress of real-world enterprise workflows.
- Revenue Protection: Prioritising cost-predictability and long-term value over short-term “wow” factors.
- Systemic Resilience: Building an architecture durable enough to transition seamlessly from sandbox to scale.
Without this shift in focus, the “wow factor” of the initial demo quickly evaporates when faced with the actual costs and risks of deployment. Consequently, momentum fades, executive sponsorship weakens, and the organisation quietly moves on, leaving behind a brittle tool that adds to the growing tally of wasted annual AI spend.
Building for Reversibility: The Architecture-First Approach
Escaping purgatory requires a fundamental inversion of the development process: moving away from “Model Testing” toward Strategic Reversibility. Instead of anchoring on a specific model, leadership must prioritise a modular architecture that treats the model as a downstream consideration.
By decoupling the “intelligence layer” from the “operational layer,” you gain the ability to swap models as the market evolves without shattering your foundation. This approach ensures that technical choices remain reversible. When you build for fit rather than just capability, you create a system that is resilient to model depreciation and price fluctuations. You shift the power back from the tech providers to the business owners.
The Solution: Establishing the Evaluation Framework
To move beyond stagnation, the focus must shift from what a model can do to how a system is measured. The primary barrier to scaling isn’t a lack of technical intelligence; it is a lack of defined success criteria that reflect operational reality.
The solution is the implementation of a rigorous Evaluation Framework—a set of non-negotiable standards that a project must meet before it is ever considered for deployment. Instead of subjective assessments of a model’s “feel” or perceived “intelligence,“ this framework tests for durability against the actual constraints of the business:
- Security Protocols: Testing for data leakage, permission management, and compliance with enterprise-wide security standards at peak volumes.
- Legal and Regulatory Auditability: Verifying that every output can be traced, logged, and audited for bias or error, ensuring the system remains defensible in a regulated environment.
- Financial and Operational Predictability: Benchmarking cost-per-task and latency behaviour to ensure that scaling doesn’t lead to exponential budget overruns or system failures.
By establishing this framework first, you create a baseline for what “good” actually looks like in a production environment. This isn’t about testing the AI’s IQ; it is about building the rigorous metrics that prove your system can function as a reliable, predictable business asset. According to McKinsey, this approach yields a 3x higher return on AI investment.
Anchoring AI to your specific enterprise constraints is what transforms speculative experiments into resilient business assets with a clear, predictable impact to P&L.